
music21, pandas and condensing sequential data
music21, developed by Michael Scott Cuthbert, is an extensively featured and well maintained Python package for computational music theory. Lately, I’ve been using its highly useful musicXML parsing capability and model of notated music in tandem with pandas DataFrames. I wanted to share a trick I’ve found for condensing rows of the dataset while keeping the sequential order intact.
The functionality of the music21 package is built on top of the Stream data structure, which allows musical material to be stored in a nested forward-linked tree structure. For my purposes I wanted a data structure with more random access features and extensive grouping and filtering capabilities than Stream. I was happy sacrificing some of the finely modeled aspects of the music21 ecosystem, holding onto just the attributes I needed for my pipeline and storing them in a pandas DataFrame. In this post I will demonstrate a cool trick for handling sequential data in pandas: combining groups of adjacent rows with groupby, while keeping the order of the DataFrame intact.
Constructing the DataFrame
Let’s take a musical score, represented as a Stream object, and read the data we need into a DataFrame. First we convert each music21 object we encounter into a row of our DataFrame using this function.
Next we iterate over our score and populate our DataFrame with the collected rows. As demonstrated in this stack overflow answer, DataFrames can be constructed substantially faster from a list of dictionaries than from sequential append operations.
Goal: Merging Adjacent Rows of the Same Type
For my application, I require that a list of consecutive rests (notated silences) be lumped together as a single rest with accumulated duration. All other rows of the dataset must be kept intact, as shown below:
Before Merging Adjacent Rests
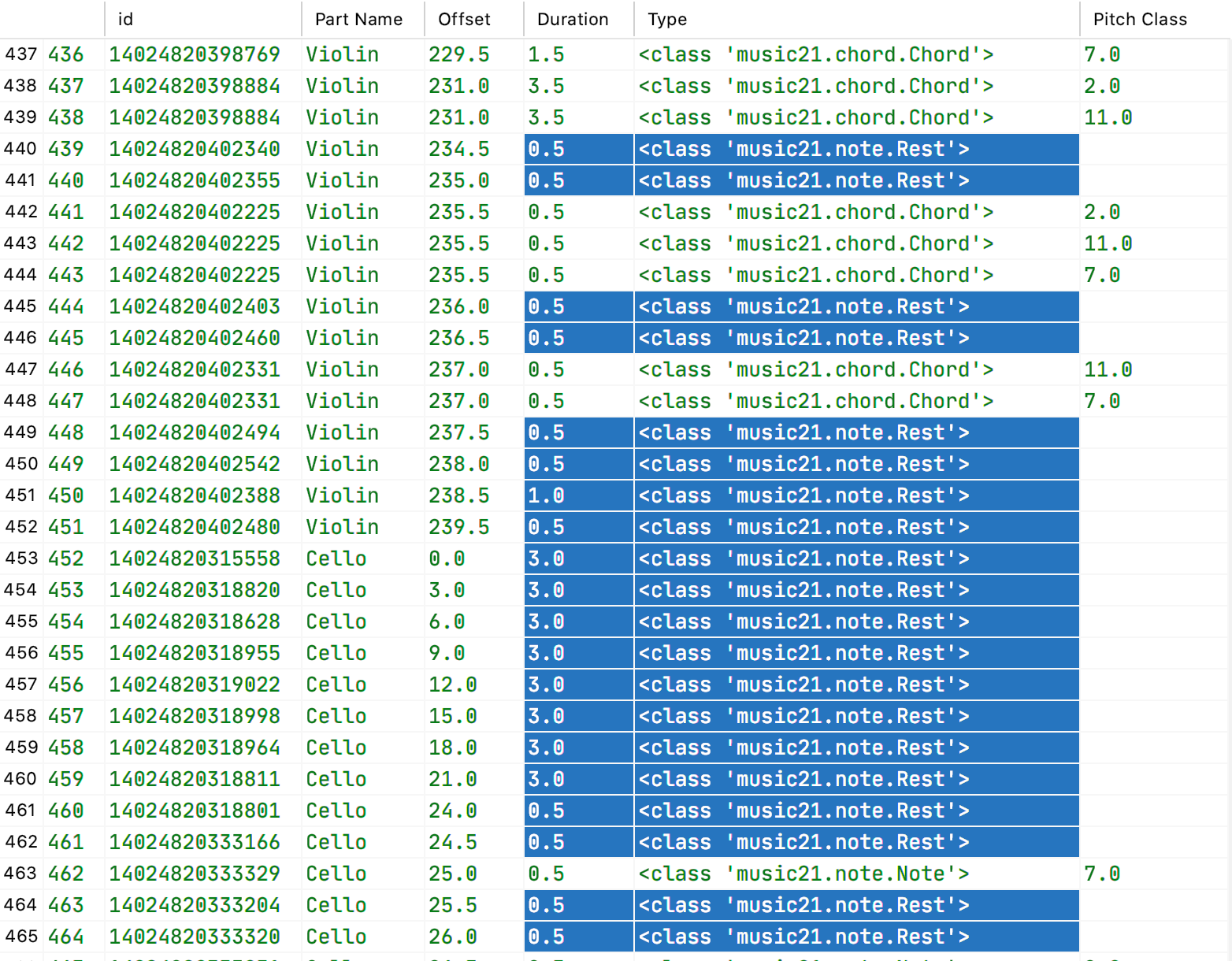
An excerpted view of the dataset before adjacent rests are merged together. Adjacent rows of Type Rest are highlighted. These are the rows that will be combined into a single row.
After Merging Adjacent Rests
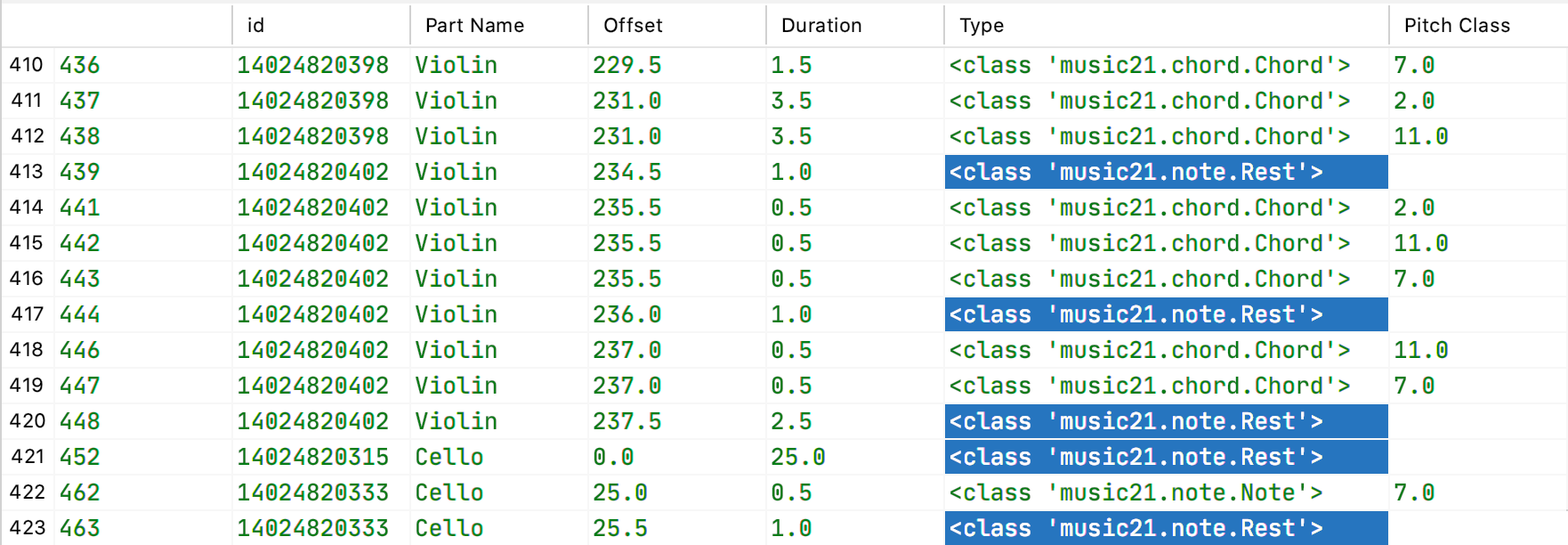
The non-rest rows are left alone. Only the rests in adjacent rows are merged together with durations summed. The one adjacent pair of rests remaining in the above view lies at the boundary of two ‘Parts’, of the Violin and the Cello, so they should not be merged.
Implementation
pandas DataFrames have an attribute method groupby, which can be used to “split-apply-combine”. This groupby method would work out-of-the-box if we wanted to merge all rests into a single row, but we need to be a little trickier to capture only adjacent Rest-Type rows and leave other row types intact - all while maintaining the order of the rows.
Here’s the function that does it!
Key Tricks
The list comprehension beginning on line 14…
… divvies up all the rest indices into groups of consecutive indices. itertools.groupby sets boundaries between groups where its callable parameter (here, a lambda) changes value. The rest of the syntax is some finagling to get the output into the form of a list of lists.
When called on any index in a run of adjacent rests, get_initial_rest is defined to return the first index in the run. When called on the index of any other row in the dataset, it just returns the same index. Hence get_initial_rest is used to map the indices of the input DataFrame to the indices of the output DataFrame, keeping the order of rows intact when runs of rests get combined. We use get_initial_rest as the labeling function that pandas.DataFrame.groupby can use to generate groups.
Finally, we define an aggregation function agg_func for groupby that sums ‘Duration’ entries and takes the first row’s element for all other columns. Note that this aggregation function does nothing to single-row groups, and does what we want for groups of rests!